
什么是正则表达式(regex)?
事实上,正则表达式是一种用于在文本中查找字符串的模式。在Java中,这种模式的原始表示总是一个字符串,即String类的一个对象。然而,并不是任何字符串都可以编译成正则表达式——只有符合创建正则表达式规则的字符串。语法在语言规范中定义。正则表达式是使用字母和数字以及元字符编写的,元字符是在正则表达式语法中具有特殊含义的字符。例如:
String regex = "java"; // The pattern is "java";
String regex = "\\d{3}"; // The pattern is three digits;
在 Java 中创建正则表达式
在 Java 中创建正则表达式包括两个简单的步骤:- 将其写成符合正则表达式语法的字符串;
- 将字符串编译成正则表达式;
Pattern。为此,我们需要调用该类的两个静态方法之一:compile。第一个方法接受一个参数——一个包含正则表达式的字符串文字,而第二个方法接受一个额外的参数来确定模式匹配设置:
public static Pattern compile (String literal)
public static Pattern compile (String literal, int flags)
flags中定义Pattern,并作为静态类变量提供给我们。例如:
Pattern pattern = Pattern.compile("java", Pattern.CASE_INSENSITIVE); // Pattern-matching will be case insensitive.
Pattern是正则表达式的构造函数。在幕后,该compile方法调用Pattern类的私有构造函数来创建编译表示。这种对象创建机制以这种方式实现,以创建不可变对象。创建正则表达式时,会检查其语法。如果字符串包含错误,则PatternSyntaxException生成 a。
正则表达式语法
正则表达式语法依赖于<([{\^-=$!|]})?*+.>字符,字符可以与字母组合。根据他们的角色,他们可以分为几组:
| 元字符 | 描述 |
|---|---|
| ^ | 一行的开头 |
| $ | 行尾 |
| \b | 单词边界 |
| \B | 非词边界 |
| \A | 输入的开始 |
| \G | 上一场比赛结束 |
| \Z | 输入结束 |
| \z | 输入结束 |
| 元字符 | 描述 |
|---|---|
| \d | 数字 |
| \D | 非数字 |
| \s | 空白字符 |
| \S | 非空白字符 |
| \w | 字母数字字符或下划线 |
| \W | 除字母、数字和下划线外的任何字符 |
| . | 任何角色 |
| 元字符 | 描述 |
|---|---|
| \t | 制表符 |
| \n | 换行符 |
| \r | 回车 |
| \F | 换行字符 |
| \u0085 | 下一行字符 |
| \u2028 | 行分隔符 |
| \u2029 | 段落分隔符 |
| 元字符 | 描述 |
|---|---|
| [abc] | 任何列出的字符(a、b 或 c) |
| [^abc] | 所列字符以外的任何字符(不是 a、b 或 c) |
| [a-zA-Z] | 合并范围(从 a 到 z 的拉丁字符,不区分大小写) |
| [广告[mp]] | 字符并集(从 a 到 d 和从 m 到 p) |
| [az&&[def]] | 字符交集 (d, e, f) |
| [az&&[^bc]] | 字符减法 (a, dz) |

| 元字符 | 描述 |
|---|---|
| ? | 一个或一个 |
| * | 零次或多次 |
| + | 一次或多次 |
| {n} | n次 |
| {n,} | n次或更多次 |
| {n,m} | 至少n次且不超过m次 |
贪心量词
关于量词你应该知道的一件事是它们有三种不同的类型:贪婪的、占有欲的和不情愿的。+您可以通过在量词后添加一个“”字符来使量词具有所有格。你通过添加“”让它变得不情愿?。例如:
"A.+a" // greedy
"A.++a" // possessive
"A.+?a" // reluctant
public static void main(String[] args) {
String text = "Fred Anna Alexander";
Pattern pattern = Pattern.compile("A.+a");
Matcher matcher = pattern.matcher(text);
while (matcher.find()) {
System.out.println(text.substring(matcher.start(), matcher.end()));
}
}
Anna Alexa
A.+a”,模式匹配执行如下:
-
指定模式中的第一个字符是拉丁字母
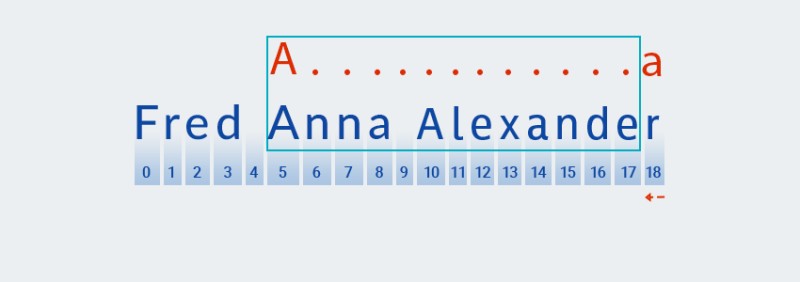
A。Matcher将它与文本的每个字符进行比较,从索引零开始。该字符F在我们的文本中的索引为零,因此Matcher遍历字符直到它与模式匹配。在我们的示例中,该字符位于索引 5 处。![Java 中的正则表达式 - 2]()
-
一旦找到与模式的第一个字符的匹配项,
Matcher就查找与其第二个字符的匹配项。在我们的例子中,它是“.”字符,代表任何字符。![Java 中的正则表达式 - 3]()
角色
n在第六个位置。它当然可以匹配“任何字符”。 -
Matcher继续检查模式的下一个字符。在我们的模式中,它包含在适用于前面字符的量词中:".+"。因为我们的模式中“任意字符”的重复次数是一次或多次,所以Matcher重复从字符串中取出下一个字符并与模式进行检查,只要匹配“任意字符”即可。在我们的例子中——直到字符串的结尾(从索引 7 到索引 18)。![Java 中的正则表达式 - 4]()
基本上,
Matcher吞噬字符串直到最后——这正是“贪婪”的意思。 -
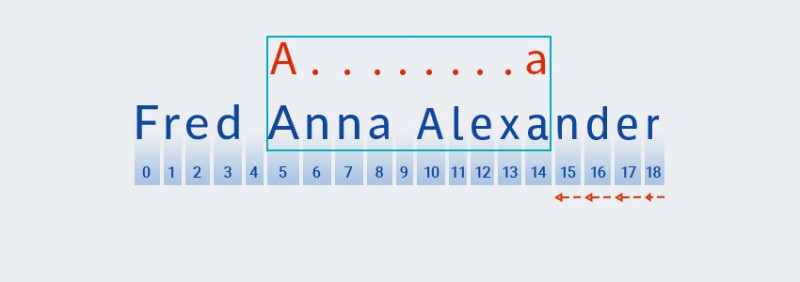
在 Matcher 到达文本末尾并完成模式的 " " 部分的检查后
A.+,它开始检查模式的其余部分:a。后面没有更多的文本,所以检查从最后一个字符开始“后退”:![Java 中的正则表达式 - 5]()
-
Matcher.+“记住”模式中“ ”部分的重复次数。此时,它会将重复次数减一,并根据文本检查较大的模式,直到找到匹配项:![Java 中的正则表达式 - 6]()



所有格量词
所有格量词很像贪婪的量词。不同之处在于,当文本已被捕获到字符串的末尾时,“后退”时没有模式匹配。换句话说,前三个阶段与贪婪量词相同。捕获整个字符串后,匹配器将模式的其余部分添加到它正在考虑的内容中,并将其与捕获的字符串进行比较。在我们的示例中,使用正则表达式“A.++a”,main 方法找不到匹配项。 
不情愿的量词
-
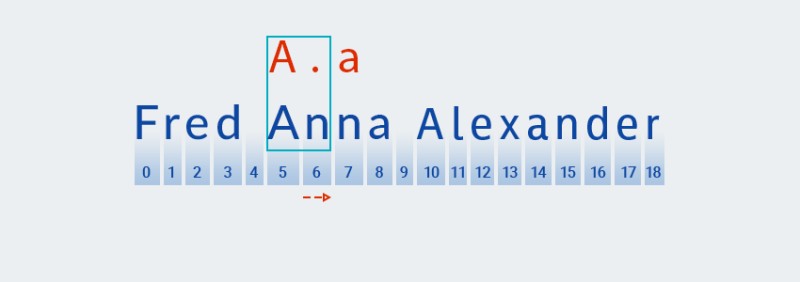
对于这些量词,与贪婪变种一样,代码根据模式的第一个字符查找匹配项:
![Java 中的正则表达式 - 8]()
-
然后它寻找与模式的下一个字符(任何字符)的匹配项:
![Java 中的正则表达式 - 9]()
-
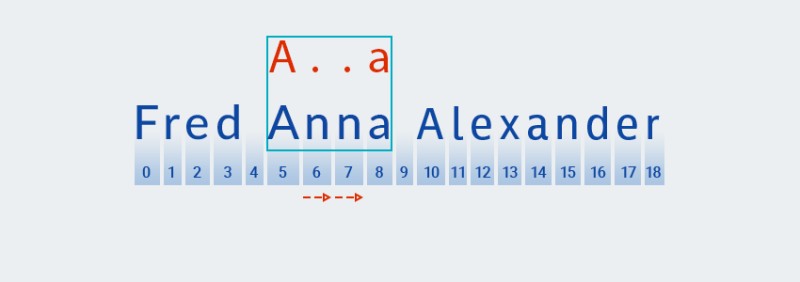
与贪心模式匹配不同,勉强模式匹配搜索最短匹配。这意味着在找到与模式的第二个字符(一个句点,对应于文本中位置 6 的字符)的匹配项后,
Matcher检查文本是否与模式的其余部分匹配——字符“a”![Java 中的正则表达式 - 10]()
-
文本与模式不匹配(即它在索引 7 处包含字符“
n”),因此Matcher添加了一个“任何字符”,因为量词表示一个或多个。然后它再次将模式与位置 5 到 8 中的文本进行比较:![Java 中的正则表达式 - 11]()


在我们的例子中,找到了一个匹配项,但我们还没有到达文本的末尾。因此,模式匹配从位置 9 重新开始,即使用类似的算法查找模式的第一个字符,并重复此过程直到文本结束。

main方法在使用模式 " " 时获得以下结果A.+?a: Anna Alexa 从我们的示例中可以看出,不同类型的量词对同一模式产生不同的结果。所以请记住这一点,并根据您的需求选择合适的品种。
在正则表达式中转义字符
因为 Java 中的正则表达式,或者更确切地说,它的原始表示是字符串文字,所以我们需要考虑有关字符串文字的 Java 规则。特别是,\Java 源代码中字符串文字中的反斜杠字符“”被解释为一个控制字符,它告诉编译器下一个字符是特殊的,必须以特殊的方式进行解释。例如:
String s = "The root directory is \nWindows"; // Move "Windows" to a new line
String s = "The root directory is \u00A7Windows"; // Insert a paragraph symbol before "Windows"
\”字符(即表示元字符)的字符串文字必须重复反斜杠以确保 Java 字节码编译器不会误解字符串。例如:
String regex = "\\s"; // Pattern for matching a whitespace character
String regex = "\"Windows\""; // Pattern for matching "Windows"
String regex = "How\\?"; // Pattern for matching "How?"
模式类的方法
该类Pattern还有其他处理正则表达式的方法:
-
String pattern()‒ 返回用于创建Pattern对象的正则表达式的原始字符串表示形式:Pattern pattern = Pattern.compile("abc"); System.out.println(pattern.pattern()); // "abc" -
static boolean matches(String regex, CharSequence input)– 让您检查作为 regex 传递的正则表达式与作为input. 退货:true——如果文本与模式匹配;
false——如果没有;例如:
System.out.println(Pattern.matches("A.+a","Anna")); // true System.out.println(Pattern.matches("A.+a","Fred Anna Alexander")); // false -
int flags()flags‒ 返回创建模式时模式参数集的值,如果未设置参数,则返回 0。例如:Pattern pattern = Pattern.compile("abc"); System.out.println(pattern.flags()); // 0 Pattern pattern = Pattern.compile("abc",Pattern.CASE_INSENSITIVE); System.out.println(pattern.flags()); // 2 -
String[] split(CharSequence text, int limit)– 将传递的文本拆分为一个String数组。该limit参数表示在文本中搜索的最大匹配数:- 如果
limit > 0-limit-1匹配; - if
limit < 0‒ 文本中的所有匹配项 - if
limit = 0‒ 文本中的所有匹配项,数组末尾的空字符串将被丢弃;
例如:
public static void main(String[] args) { String text = "Fred Anna Alexa"; Pattern pattern = Pattern.compile("\\s"); String[] strings = pattern.split(text,2); for (String s : strings) { System.out.println(s); } System.out.println("---------"); String[] strings1 = pattern.split(text); for (String s : strings1) { System.out.println(s); } }控制台输出:
Fred Anna Alexa --------- Fred Anna Alexa下面我们将考虑用于创建
Matcher对象的类的另一个方法。 - 如果
匹配器类的方法
Matcher创建该类的实例以执行模式匹配。Matcher是正则表达式的“搜索引擎”。要执行搜索,我们需要给它两个东西:一个模式和一个起始索引。为了创建一个Matcher对象,该类Pattern提供了以下方法: рublic Matcher matcher(CharSequence input) 该方法采用一个字符序列,将对其进行搜索。这是实现接口的类的实例CharSequence。您不仅可以传递 a String,还可以传递StringBuffer、StringBuilder、Segment或CharBuffer。模式是调用方法Pattern的对象。matcher创建匹配器的示例:
Pattern p = Pattern.compile("a*b"); // Create a compiled representation of the regular expression
Matcher m = p.matcher("aaaaab"); // Create a "search engine" to search the text "aaaaab" for the pattern "a*b"
boolean find()方法在文本中查找下一个匹配项。我们可以使用此方法和循环语句来分析整个文本作为事件模型的一部分。换句话说,我们可以在事件发生时执行必要的操作,即当我们在文本中找到匹配项时。例如,我们可以使用此类的int start()和int end()方法来确定匹配项在文本中的位置。并且我们可以使用String replaceFirst(String replacement)和String replaceAll(String replacement)方法将匹配项替换为替换参数的值。例如:

public static void main(String[] args) {
String text = "Fred Anna Alexa";
Pattern pattern = Pattern.compile("A.+?a");
Matcher matcher = pattern.matcher(text);
while (matcher.find()) {
int start=matcher.start();
int end=matcher.end();
System.out.println("Match found: " + text.substring(start, end) + " from index "+ start + " through " + (end-1));
}
System.out.println(matcher.replaceFirst("Ira"));
System.out.println(matcher.replaceAll("Mary"));
System.out.println(text);
}
Match found: Anna from index 5 through 8
Match found: Alexa from index 10 through 14
Fred Ira Alexa
Fred Mary Mary
Fred Anna Alexa
replaceFirst和replaceAll方法创建了一个新String对象——一个字符串,其中原始文本中的模式匹配被作为参数传递给该方法的文本替换。此外,该replaceFirst方法仅替换第一个匹配项,但该replaceAll方法替换文本中的所有匹配项。原文保持不变。和类最频繁的正Pattern则Matcher表达式操作直接内置到String类中。这些是诸如split、matches、replaceFirst和 之类的方法replaceAll。但在幕后,这些方法使用Pattern和Matcher类。因此,如果您想在程序中替换文本或比较字符串而不编写任何额外代码,请使用String班级。如果您需要更高级的功能,请记住Pattern和Matcher类。
结论
在 Java 程序中,正则表达式由遵循特定模式匹配规则的字符串定义。执行代码时,Java 机器将这个字符串编译成对象Pattern,并使用Matcher对象在文本中查找匹配项。正如我在开头所说的,人们经常把正则表达式搁置一旁,认为它们是一个困难的话题。但是如果您了解基本语法、元字符和字符转义,并研究正则表达式的示例,那么您会发现它们比乍看起来要简单得多。
|
更多阅读: |
|---|
GO TO FULL VERSION