
Vad är ett reguljärt uttryck (regex)?
Faktum är att ett reguljärt uttryck är ett mönster för att hitta en sträng i text. I Java är den ursprungliga representationen av detta mönster alltid en sträng, dvs ett objekt i klassenString. Det är dock inte vilken sträng som helst som kan kompileras till ett reguljärt uttryck - bara strängar som följer reglerna för att skapa reguljära uttryck. Syntaxen definieras i språkspecifikationen. Reguljära uttryck skrivs med bokstäver och siffror, samt metatecken, som är tecken som har speciell betydelse i reguljära uttryckssyntax. Till exempel:
String regex = "java"; // The pattern is "java";
String regex = "\\d{3}"; // The pattern is three digits;
Skapa reguljära uttryck i Java
Att skapa ett reguljärt uttryck i Java innebär två enkla steg:- skriv det som en sträng som överensstämmer med syntaxen för reguljära uttryck;
- kompilera strängen till ett reguljärt uttryck;
Patternobjekt. För att göra detta måste vi anropa en av klassens två statiska metoder: compile. Den första metoden tar ett argument - en bokstavlig sträng som innehåller det reguljära uttrycket, medan den andra tar ett extra argument som bestämmer inställningarna för mönstermatchning:
public static Pattern compile (String literal)
public static Pattern compile (String literal, int flags)
flagsparametern är definierad i Patternklass och är tillgänglig för oss som statiska klassvariabler. Till exempel:
Pattern pattern = Pattern.compile("java", Pattern.CASE_INSENSITIVE); // Pattern-matching will be case insensitive.
Patternär klassen en konstruktor för reguljära uttryck. Under huven compileanropar metoden Patternklassens privata konstruktör för att skapa en kompilerad representation. Denna objektskapande mekanism implementeras på detta sätt för att skapa oföränderliga objekt. När ett reguljärt uttryck skapas kontrolleras dess syntax. Om strängen innehåller fel PatternSyntaxExceptiongenereras a.
Syntax för reguljära uttryck
Syntaxen för reguljära uttryck är beroende av<([{\^-=$!|]})?*+.>tecknen, som kan kombineras med bokstäver. Beroende på deras roll kan de delas in i flera grupper:
| Metakaraktär | Beskrivning |
|---|---|
| ^ | början av en rad |
| $ | slutet av en rad |
| \b | ordgräns |
| \B | icke-ordsgräns |
| \A | början av inmatningen |
| \G | slutet av föregående match |
| \Z | slutet av inmatningen |
| \z | slutet av inmatningen |
| Metakaraktär | Beskrivning |
|---|---|
| \d | siffra |
| \D | icke-siffrig |
| \s | blanktecken |
| \S | tecken som inte är blanksteg |
| \w | alfanumeriskt tecken eller understreck |
| \W | alla tecken utom bokstäver, siffror och understreck |
| . | vilken karaktär som helst |

| Metakaraktär | Beskrivning |
|---|---|
| \t | tabbtecken |
| \n | nyradstecken |
| \r | vagnretur |
| \f | linjematningskaraktär |
| \u0085 | nästa rads tecken |
| \u2028 | linjeavskiljare |
| \u2029 | styckeavskiljare |
| Metakaraktär | Beskrivning |
|---|---|
| [abc] | något av de listade tecknen (a, b eller c) |
| [^abc] | något annat tecken än de som anges (inte a, b eller c) |
| [a-zA-Z] | sammanslagna intervall (latinska tecken från a till z, skiftlägesokänslig) |
| [annons[mp]] | förening av tecken (från a till d och från m till p) |
| [az&&[def]] | skärningspunkten av tecken (d, e, f) |
| [az&&[^bc]] | subtraktion av tecken (a, dz) |
| Metakaraktär | Beskrivning |
|---|---|
| ? | en eller ingen |
| * | noll eller fler gånger |
| + | en eller flera gånger |
| {n} | n gånger |
| {n,} | n eller fler gånger |
| {n,m} | minst n gånger och inte mer än m gånger |
Giriga kvantifierare
En sak du bör veta om kvantifierare är att de finns i tre olika varianter: giriga, possessiva och motvilliga. Du gör en kvantifierare possessiv genom att lägga till ett "+" tecken efter kvantifieraren. Du gör det motvilligt genom att lägga till " " ?. Till exempel:
"A.+a" // greedy
"A.++a" // possessive
"A.+?a" // reluctant
public static void main(String[] args) {
String text = "Fred Anna Alexander";
Pattern pattern = Pattern.compile("A.+a");
Matcher matcher = pattern.matcher(text);
while (matcher.find()) {
System.out.println(text.substring(matcher.start(), matcher.end()));
}
}
Anna Alexa
A.+a" utförs mönstermatchning enligt följande:
-
Det första tecknet i det angivna mönstret är den latinska bokstaven
A.Matcherjämför det med varje tecken i texten, med början från index noll. TecknetFär på index noll i vår text, såMatcherdet går igenom tecknen tills det matchar mönstret. I vårt exempel finns detta tecken i index 5.![Reguljära uttryck i Java - 2]()
-
När en matchning med mönstrets första tecken hittats,
Matcherletar du efter en matchning med dess andra tecken. I vårt fall är det.tecknet " " som står för vilken karaktär som helst.![Reguljära uttryck i Java - 3]()
Karaktären
när på sjätte plats. Det kvalificerar verkligen som en match för "vilken karaktär som helst". -
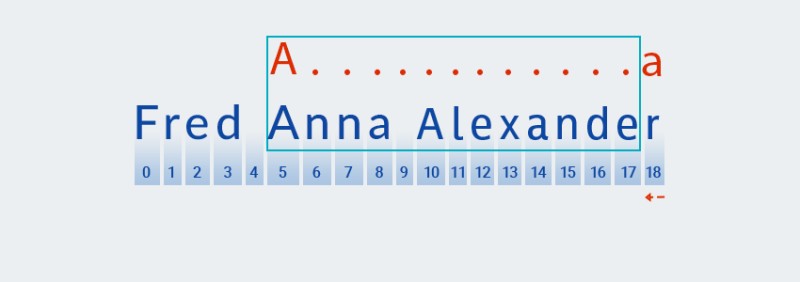
Matcherfortsätter för att kontrollera nästa tecken i mönstret. I vårt mönster ingår det i kvantifieraren som gäller för föregående tecken: " ".+. Eftersom antalet upprepningar av "valfri karaktär" i vårt mönster är en eller flera gånger,Matchertar upprepade gånger nästa tecken från strängen och kontrollerar det mot mönstret så länge som det matchar "valfritt tecken". I vårt exempel — till slutet av strängen (från index 7 till index 18).![Reguljära uttryck i Java - 4]()
I grund och botten
Matcherslukar snöret till slutet - det är precis vad som menas med "girig". -
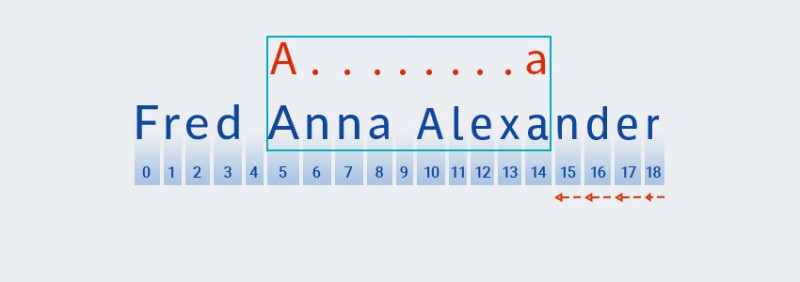
När Matcher når slutet av texten och avslutar kontrollen för " "
A.+delen av mönstret, börjar den kontrollera för resten av mönstret:a. Det finns ingen mer text framåt, så kontrollen fortsätter med att "backa av", med början från det sista tecknet:![Reguljära uttryck i Java - 5]()
-
Matcher"kommer ihåg" antalet repetitioner i " ".+-delen av mönstret. Vid denna tidpunkt minskar den antalet repetitioner med en och kontrollerar det större mönstret mot texten tills en matchning hittas:![Reguljära uttryck i Java - 6]()



Besittande kvantifierare
Possessiva kvantifierare är mycket som giriga. Skillnaden är att när text har fångats till slutet av strängen finns det ingen mönstermatchning när man "backar". Med andra ord, de tre första stegen är desamma som för giriga kvantifierare. Efter att ha fångat hela strängen lägger matcharen till resten av mönstret till vad den överväger och jämför det med den fångade strängen. I vårt exempel, med det reguljära uttrycket "A.++a", hittar huvudmetoden ingen matchning. 
Motvilliga kvantifierare
-
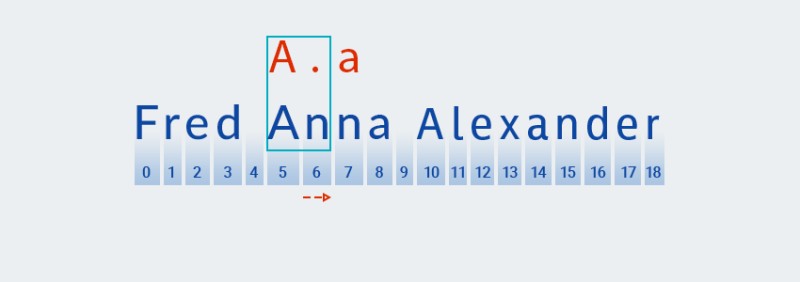
För dessa kvantifierare, som med den giriga varianten, letar koden efter en matchning baserat på det första tecknet i mönstret:
![Reguljära uttryck i Java - 8]()
-
Sedan letar det efter en matchning med mönstrets nästa tecken (valfritt tecken):
![Reguljära uttryck i Java - 9]()
-
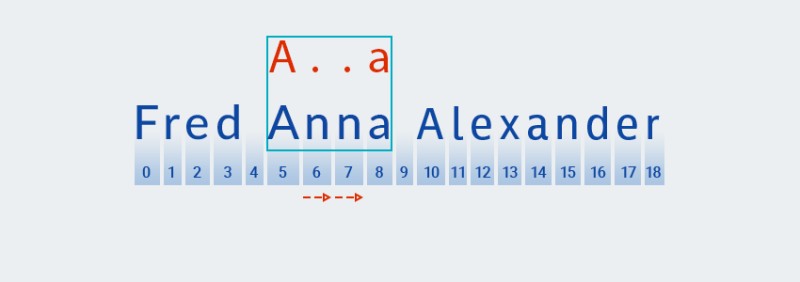
Till skillnad från girig mönstermatchning, söks den kortaste matchningen efter i motvillig mönstermatchning. Detta innebär att efter att ha hittat en matchning med mönstrets andra tecken (en punkt, som motsvarar tecknet på position 6 i texten,
Matcherkontrollerar om texten matchar resten av mönstret — tecknet "a"![Reguljära uttryck i Java - 10]()
-
Texten stämmer inte överens med mönstret (dvs den innehåller tecknet "
n" vid index 7), såMatcherlägger till mer ett "valfritt tecken", eftersom kvantifieraren indikerar en eller flera. Sedan jämför den återigen mönstret med texten i positionerna 5 till 8:![Reguljära uttryck i Java - 11]()


I vårt fall hittas en matchning, men vi har inte nått slutet av texten än. Därför startar mönstermatchningen om från position 9, dvs mönstrets första tecken letas efter med en liknande algoritm och detta upprepas till slutet av texten.

mainfår metoden följande resultat när man använder mönstret " " A.+?a: Anna Alexa Som du kan se från vårt exempel ger olika typer av kvantifierare olika resultat för samma mönster. Så tänk på detta och välj rätt sort baserat på vad du letar efter.
Escapende tecken i reguljära uttryck
Eftersom ett reguljärt uttryck i Java, eller snarare dess ursprungliga representation, är en strängliteral, måste vi ta hänsyn till Java-regler angående strängliteraler. I synnerhet tolkas omvänt snedstreck " "\i strängliterals i Java-källkod som ett kontrolltecken som talar om för kompilatorn att nästa tecken är speciellt och måste tolkas på ett speciellt sätt. Till exempel:
String s = "The root directory is \nWindows"; // Move "Windows" to a new line
String s = "The root directory is \u00A7Windows"; // Insert a paragraph symbol before "Windows"
\"-tecken (dvs. för att indikera metatecken) måste upprepa omvända snedstreck för att säkerställa att Java-bytekodkompilatorn inte misstolkar strängen. Till exempel:
String regex = "\\s"; // Pattern for matching a whitespace character
String regex = "\"Windows\""; // Pattern for matching "Windows"
String regex = "How\\?"; // Pattern for matching "How?"
Metoder i klassen Mönster
KlassenPatternhar andra metoder för att arbeta med reguljära uttryck:
-
String pattern()‒ returnerar det reguljära uttryckets ursprungliga strängrepresentation som användes för att skapa objektetPattern:Pattern pattern = Pattern.compile("abc"); System.out.println(pattern.pattern()); // "abc" -
static boolean matches(String regex, CharSequence input)– låter dig kontrollera det reguljära uttrycket som skickas som regex mot texten som skickas sominput. Returnerar:sant – om texten matchar mönstret;
falskt – om det inte gör det;Till exempel:
System.out.println(Pattern.matches("A.+a","Anna")); // true System.out.println(Pattern.matches("A.+a","Fred Anna Alexander")); // false -
int flags()‒ returnerar värdet för mönstretsflagsparameteruppsättning när mönstret skapades eller 0 om parametern inte var inställd. Till exempel:Pattern pattern = Pattern.compile("abc"); System.out.println(pattern.flags()); // 0 Pattern pattern = Pattern.compile("abc",Pattern.CASE_INSENSITIVE); System.out.println(pattern.flags()); // 2 -
String[] split(CharSequence text, int limit)– delar upp den skickade texten i enStringarray. Parameternlimitanger det maximala antalet matchningar som söks efter i texten:- om
limit > 0‒limit-1matchar; - om
limit < 0‒ alla matchar i texten - om
limit = 0‒ alla matchningar i texten kasseras tomma strängar i slutet av arrayen;
Till exempel:
public static void main(String[] args) { String text = "Fred Anna Alexa"; Pattern pattern = Pattern.compile("\\s"); String[] strings = pattern.split(text,2); for (String s : strings) { System.out.println(s); } System.out.println("---------"); String[] strings1 = pattern.split(text); for (String s : strings1) { System.out.println(s); } }Konsolutgång:
Fred Anna Alexa --------- Fred Anna AlexaNedan kommer vi att överväga en annan av klassens metoder som används för att skapa ett
Matcherobjekt. - om
Metoder i Matcher-klassen
Instanser avMatcherklassen skapas för att utföra mönstermatchning. Matcherär "sökmotorn" för reguljära uttryck. För att utföra en sökning måste vi ge den två saker: ett mönster och ett startindex. För att skapa ett Matcherobjekt Patterntillhandahåller klassen följande metod: рublic Matcher matcher(CharSequence input) Metoden tar en teckensekvens som kommer att genomsökas. Detta är en instans av en klass som implementerar gränssnittet CharSequence. Du kan passera inte bara en String, utan också en StringBuffer, StringBuilder, Segment, eller CharBuffer. Mönstret är ett Patternobjekt på vilket matchermetoden kallas. Exempel på att skapa en matchare:
Pattern p = Pattern.compile("a*b"); // Create a compiled representation of the regular expression
Matcher m = p.matcher("aaaaab"); // Create a "search engine" to search the text "aaaaab" for the pattern "a*b"

boolean find()letar efter nästa matchning i texten. Vi kan använda denna metod och en loop-sats för att analysera en hel text som en del av en händelsemodell. Med andra ord kan vi utföra nödvändiga operationer när en händelse inträffar, dvs när vi hittar en matchning i texten. Till exempel kan vi använda denna klass int start()och int end()metoder för att bestämma en matchs position i texten. Och vi kan använda metoderna String replaceFirst(String replacement)och String replaceAll(String replacement)för att ersätta matchningar med värdet på ersättningsparametern. Till exempel:
public static void main(String[] args) {
String text = "Fred Anna Alexa";
Pattern pattern = Pattern.compile("A.+?a");
Matcher matcher = pattern.matcher(text);
while (matcher.find()) {
int start=matcher.start();
int end=matcher.end();
System.out.println("Match found: " + text.substring(start, end) + " from index "+ start + " through " + (end-1));
}
System.out.println(matcher.replaceFirst("Ira"));
System.out.println(matcher.replaceAll("Mary"));
System.out.println(text);
}
Match found: Anna from index 5 through 8
Match found: Alexa from index 10 through 14
Fred Ira Alexa
Fred Mary Mary
Fred Anna Alexa
replaceFirstoch replaceAllskapar ett nytt Stringobjekt — en sträng där mönstermatchningar i originaltexten ersätts av texten som skickas till metoden som ett argument. Dessutom replaceFirstersätter metoden endast den första matchningen, men replaceAllmetoden ersätter alla matchningar i texten. Originaltexten förblir oförändrad. Klasserna Patternochs Matchervanligaste regex-operationer är inbyggda direkt i Stringklassen. Det här är metoder som split, matches, replaceFirst, och replaceAll. Men under huven använder dessa metoder klasserna Patternoch . MatcherSå om du vill ersätta text eller jämföra strängar i ett program utan att skriva någon extra kod, använd metoderna iStringklass. Om du behöver mer avancerade funktioner, kom ihåg klasserna Patternoch .Matcher
Slutsats
I ett Java-program definieras ett reguljärt uttryck av en sträng som följer specifika mönstermatchningsregler. När kod körs kompilerar Java-maskinen denna sträng till ettPatternobjekt och använder ett Matcherobjekt för att hitta matchningar i texten. Som jag sa i början, skjuter folk ofta upp vanliga uttryck för senare, eftersom de anser att de är ett svårt ämne. Men om du förstår den grundläggande syntaxen, metatecken och teckenflykt, och studerar exempel på reguljära uttryck, kommer du att upptäcka att de är mycket enklare än de ser ut vid första anblicken.
|
Mer läsning: |
|---|
GO TO FULL VERSION